
In 2019, Cynthia Rudin published a landmark paper in Nature Machine Intelligence with a title that doubled as a challenge: "Stop Explaining Black Box Machine Learning Models for High Stakes Decisions and Use Interpretable Models Instead." The paper, now cited over 5,000 times, argued that when the stakes are high, the default should not be a complex model with a post-hoc explanation bolted on. The default should be a model you can understand from the start.
Seven years later, the debate is far from settled, but the evidence has shifted significantly. A 2024 study in Business and Information Systems Engineering found no strict trade-off between predictive performance and model interpretability for tabular data. New-generation glass-box models like Explainable Boosting Machines now match gradient-boosted tree accuracy while remaining fully interpretable. And the EU AI Act, reaching full enforcement in August 2026, now requires that high-risk AI systems be "sufficiently transparent to enable deployers to interpret a system's output."
This post is a practical guide to the interpretable-versus-black-box decision. It is not a theoretical overview. It is written for practitioners, data scientists, risk professionals, and decision-makers who need to choose a model and defend that choice to regulators, auditors, or leadership. If you have read our introduction to why explainable AI matters, this post goes deeper: into the specific models, the specific limitations of post-hoc methods, and the decision framework you need to make the right call.
What You Will Learn
· What interpretable and black-box models actually are, with concrete examples from credit risk and finance
· Why the "accuracy vs interpretability" trade-off is often overstated, and what recent research shows
· How Explainable Boosting Machines (EBMs) offer a third option between simple and complex models
· Where SHAP and LIME fall short, and why post-hoc explanation is not the same as inherent transparency
· What the EU AI Act requires for model transparency and how that shapes model selection
· A practical decision framework for choosing between interpretable and black-box approaches
What Are Interpretable and Black-Box Models?
An interpretable model is one whose internal logic can be directly understood by a human being. When a logistic regression model denies a credit application, an analyst can point to the specific features and their exact weights that produced the decision. The same is true for decision trees, scorecards, and generalised additive models (GAMs). The reasoning is built into the model structure itself.
A black-box model is one whose internal logic is too complex for humans to trace directly. Deep neural networks, large random forests, and gradient-boosted ensembles with hundreds of trees fall into this category. These models can achieve strong predictive performance, but understanding why they made a specific prediction requires external explanation tools rather than direct inspection.
This distinction matters because it shapes how you validate, audit, debug, and defend a model in production. If you work in financial services, where regulatory scrutiny is highest, the type of model you choose determines not just accuracy but also your ability to explain decisions to customers, regulators, and internal model validation teams.
The Spectrum, Not the Binary
In practice, interpretability is not a binary property. It exists on a spectrum:
· Fully interpretable: logistic regression, scorecards, small decision trees, rule lists
· Glass-box with complexity: Explainable Boosting Machines (EBMs), constrained GAMs, GAMI-Net
· Partially interpretable: small random forests, shallow gradient-boosted trees with post-hoc tools
· Black-box: deep neural networks, large gradient-boosted ensembles, transformer-based models
The question is not "interpretable or black-box?" The question is "how much transparency does this decision require, and what is the simplest model that meets both performance and transparency thresholds?"
The Accuracy vs Interpretability Trade-Off: What the Evidence Actually Shows
For years, the dominant assumption in machine learning was that you had to sacrifice accuracy for interpretability. Want a model you can explain? Accept lower performance. Want the best predictions? Accept a black box.
This assumption is increasingly challenged by evidence. The BISE 2024 study found that for structured, tabular data (which dominates finance, healthcare, and operations), new-generation interpretable models capture complex, non-linear patterns while remaining fully transparent. Research from the Harvard Data Science Review reached a similar conclusion: in several high-stakes domains, black-box models offered no meaningful accuracy advantage over interpretable alternatives.
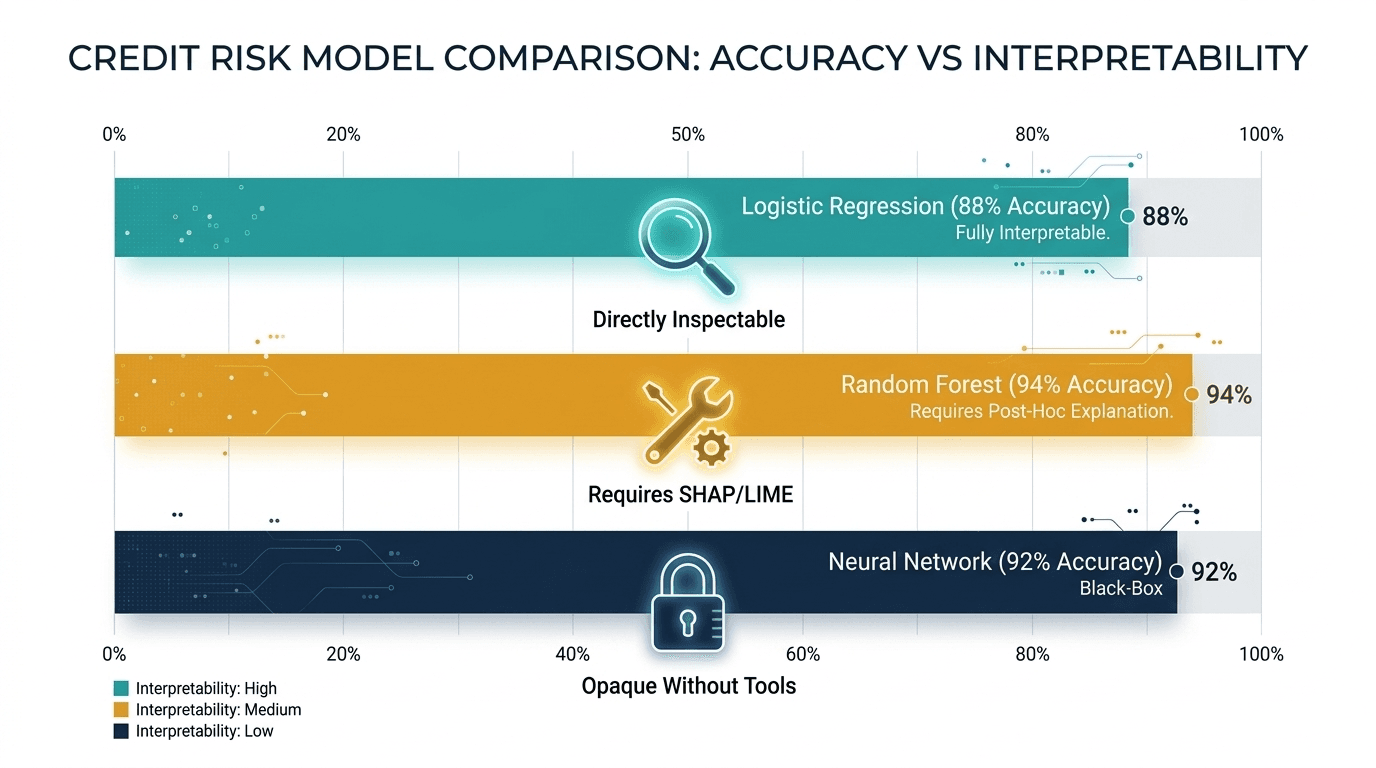
Credit Risk: A Concrete Comparison
Consider a credit risk study comparing three approaches. A random forest achieved 94% accuracy. A neural network reached 92%. Logistic regression came in at 88%. On the surface, the random forest wins. But look deeper:
· The 6-percentage-point gap between logistic regression and random forest sounds significant, but in production credit scoring, where data drift, regulatory audits, and customer disputes are constant, that gap often narrows or disappears entirely.
· The logistic regression model can be fully explained to a regulator in minutes. The random forest requires SHAP values, partial dependence plots, and careful framing to approximate the same level of transparency.
· Model validation teams in banks routinely reject black-box models regardless of accuracy, because the cost of unexplainability (regulatory penalties, customer complaints, reputational risk) exceeds the marginal performance gain.
This does not mean black-box models are never justified. It means the burden of proof should be on the complex model. If a simpler model achieves comparable results, it should be the default.
The Third Option: Explainable Boosting Machines
One of the most significant developments in interpretable machine learning is the Explainable Boosting Machine (EBM), part of Microsoft's open-source InterpretML library. EBMs are glass-box models that use a generalised additive model (GAM) structure with automatic interaction detection. They train one feature at a time in round-robin fashion, building smooth, non-linear functions for each feature while capturing pairwise interactions.
What makes EBMs remarkable is their combination of properties:
· They match or approach gradient-boosted tree accuracy on tabular data, because the round-robin training and interaction detection capture complex patterns.
· They are fully interpretable: you can inspect exactly how each feature contributes to the prediction and visualise the learned shape functions.
· They handle missing values and mixed data types natively, reducing the need for extensive preprocessing.
· They have been validated in healthcare (achieving an AUC of 0.901 in a rheumatoid arthritis study) and financial applications.
EBMs represent a category that barely existed when the "accuracy vs interpretability" framing was established. They are not simple logistic regressions. They are not black boxes. They are modern glass-box models that challenge the assumption that you must choose between understanding and performance. For practitioners evaluating foundational tools for data careers, InterpretML deserves a place on the list alongside scikit-learn and XGBoost.
SHAP and LIME: Useful but Imperfect
When teams choose a black-box model, the most common strategy for transparency is to apply post-hoc explanation methods like SHAP (SHapley Additive exPlanations) and LIME (Local Interpretable Model-agnostic Explanations). These tools generate approximate explanations for individual predictions after the model has been trained. They have become standard practice, and for good reason: they work across model types, they produce feature-level importance scores, and they are well-supported in Python.
But recent research documents important limitations that practitioners should understand before relying on these methods in high-stakes contexts:
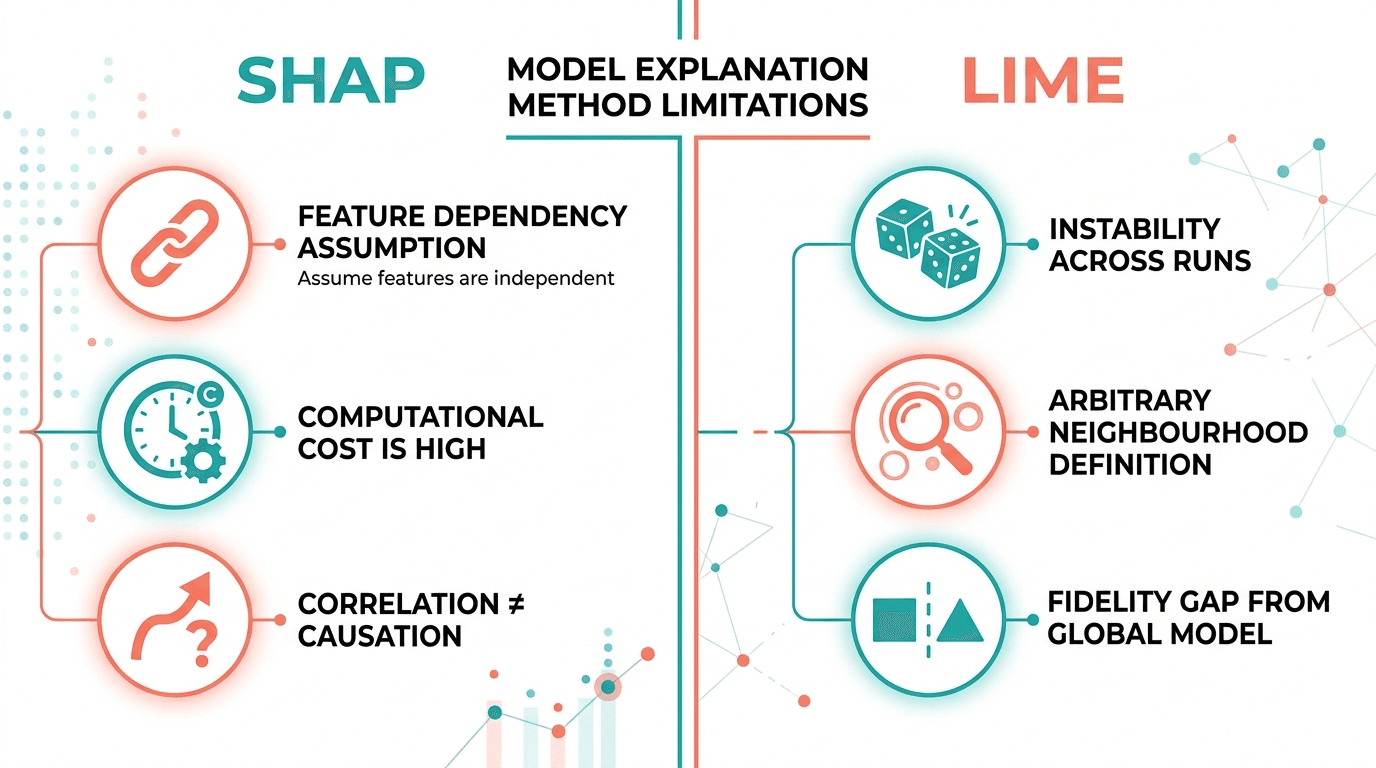
SHAP Limitations
· Feature independence assumption: SHAP values assume features are independent, which is often violated in real datasets. When features are correlated (income and credit limit, age and years of employment), SHAP can assign misleading importance scores.
· Computational cost: KernelSHAP, the model-agnostic variant, is computationally expensive for large datasets and complex models. TreeSHAP is faster but limited to tree-based models.
· Explanation is not causation: SHAP shows which features influenced a prediction, not whether those features caused the outcome. This distinction matters for regulatory explanations.
LIME Limitations
· Instability: LIME uses random perturbations to generate local explanations. Run it twice on the same prediction and you may get different results. This instability undermines trust in production settings.
· Neighbourhood definition: LIME approximates the black-box model locally, but the definition of "local" is arbitrary. Change the neighbourhood size and the explanation changes.
· Fidelity gap: the simple surrogate model LIME fits may not faithfully represent the black-box model's behaviour in the local region, leading to explanations that are plausible but inaccurate.
None of this means SHAP and LIME should be abandoned. They remain valuable for model development, debugging, and exploratory analysis. But relying on them as your sole transparency mechanism in a regulated, high-stakes environment is a risk. As Cynthia Rudin argues, if you can use an interpretable model that does not need a post-hoc explanation, you should.
What the EU AI Act Requires for Model Transparency
The EU AI Act is the most comprehensive AI regulation in the world, and its transparency requirements directly affect model selection. Article 13 requires that high-risk AI systems "be designed and developed in such a way that their operation is sufficiently transparent to enable deployers to interpret a system's output and use it appropriately."
For financial services, this is not abstract. Credit scoring models, fraud detection systems, insurance pricing algorithms, and AML classifiers are all classified as high-risk under the Act. If your model cannot provide sufficient transparency, you face penalties of up to 35 million euros or 7% of global turnover.
The Act does not mandate interpretable models specifically. It mandates transparency. In principle, a black-box model with robust post-hoc explanation could satisfy this requirement. But in practice, the combination of Article 13 transparency obligations, existing Basel III model validation requirements, GDPR's right to explanation, and internal audit expectations makes inherently interpretable models the path of least regulatory resistance.
Organisations that choose black-box models for high-risk applications should prepare for significantly higher documentation, validation, and audit costs. As our analysis of what NeuroNomixer stands for argues, the governance gap in AI is real, and model selection is where governance starts.
A Practical Decision Framework
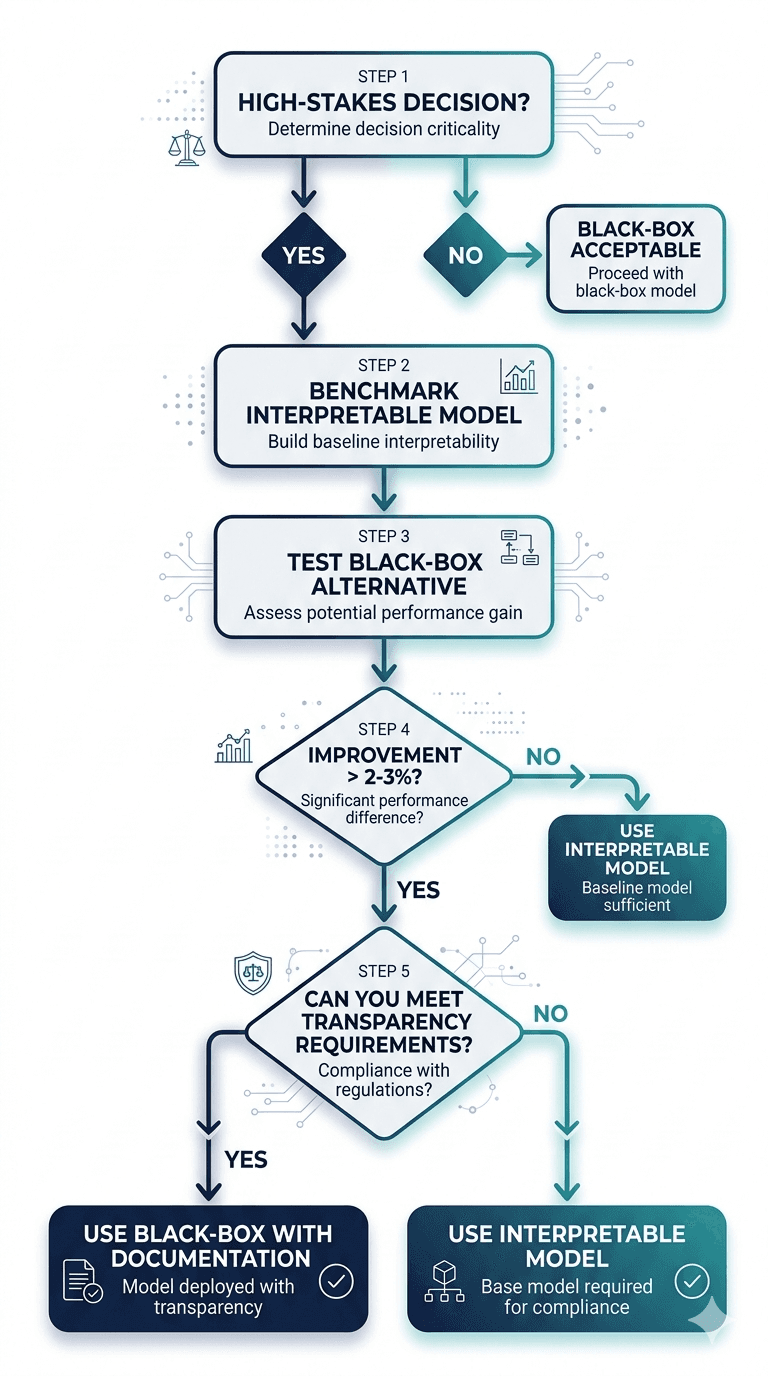
Based on the evidence, here is a decision framework for choosing between interpretable and black-box models:
Step 1: Define the Stakes
Is this a high-stakes decision? Credit approvals, medical diagnoses, criminal sentencing, and insurance pricing all qualify. If the answer is yes, start with an interpretable model. The burden of proof is on the black box to justify itself.
Step 2: Benchmark with Interpretable Models First
Train a logistic regression, a scorecard, or an EBM as your baseline. Measure performance against a well-defined metric (AUC, F1, precision at a fixed recall threshold). Document the results. This is your transparency floor.
Step 3: Test Black-Box Alternatives
Train a gradient-boosted model or neural network on the same data. Compare performance against the interpretable baseline. If the improvement is marginal (less than 2 to 3 percentage points on your primary metric), the interpretable model should win by default.
Step 4: Evaluate the Full Cost of Complexity
If the black-box model shows meaningful improvement, ask:
· Can we explain this model sufficiently to satisfy regulators, auditors, and customers?
· What is the additional cost of SHAP/LIME infrastructure, model monitoring, and documentation?
· How will we handle model drift detection and retraining for a model we cannot fully inspect?
· Does this improvement justify the regulatory, reputational, and operational risks of reduced transparency?
Step 5: Document and Defend
Whatever you choose, document the rationale. If you chose the interpretable model, document why. If you chose the black box, document the performance gap, the explanation strategy, and the risk mitigation plan. In a regulatory environment shaped by the EU AI Act and Basel III, "it performed 1% better" is not a sufficient justification for opacity.
Looking Ahead: When Black Boxes Are Justified
This post has argued for interpretable models as the default for high-stakes decisions. But there are legitimate use cases for black-box models:
· Unstructured data: image recognition, natural language processing, and speech recognition require deep learning architectures that are inherently complex. Interpretability tools for these domains are improving but remain limited.
· Low-stakes, high-volume predictions: product recommendations, ad targeting, and similar applications where individual predictions do not require human review or regulatory justification.
· Research and discovery: when the goal is to find patterns or generate hypotheses rather than to make individual decisions, model transparency matters less than predictive power.
Emerging hybrid approaches are also promising. Selective learning frameworks use simpler interpretable models where sufficient and route only the difficult cases to complex models, combining transparency with performance where it matters most.
In upcoming posts, we will explore how these principles apply specifically to credit risk modelling, where the trade-off between transparency and accuracy has the most direct consequences for consumers and institutions alike.
Conclusion: Interpretability Is Not a Compromise
The framing of "accuracy versus interpretability" has dominated machine learning discourse for over a decade. But the evidence increasingly shows that for tabular, structured data in high-stakes domains, this trade-off is often illusory. Modern interpretable models like EBMs close the performance gap. Post-hoc methods like SHAP and LIME, while useful, are not substitutes for inherent transparency. And the regulatory landscape, led by the EU AI Act, is moving decisively toward transparency as a requirement rather than a preference.
For practitioners, the takeaway is clear: start with interpretable models. Benchmark them properly. Only reach for a black box when the interpretable alternative genuinely cannot meet your performance requirements, and when you have a documented plan for the additional transparency, validation, and regulatory cost that complexity brings.
Understanding how data flows through organisations and how data-driven decisions are made in practice is the foundation for good model selection. The model is only one piece. The governance, the documentation, the human oversight: these are what make AI trustworthy.
Continue Reading
· Why Explainable AI Matters More Than You Think
· The EU AI Act in 2026: What It Actually Means for Business and Innovation
· Exploring How Machine Learning and Analytics Shape the Future