
The world will generate an estimated 221 zettabytes of data in 2026, roughly 2.5 quintillion bytes every single day. That number is staggering, but it obscures a more important question: what actually happens to all that data after it is created?
For most organisations, the answer is messy. Data is generated in one system, copied to another, transformed in a third, stored somewhere it may never be found again, and rarely deleted when it should be. The result is sprawl, risk, and missed insight. Understanding the data lifecycle, the journey data takes from the moment it is created to the moment it is destroyed, is the foundation of good data management, effective analytics, and regulatory compliance.
This post walks through each stage of the data lifecycle, explains what happens at every step, and grounds the theory in practical examples from financial services. Whether you are a data professional building pipelines or a business leader trying to understand how information flows through your organisation, this is the map you need.
What You Will Learn
· The six core stages of the data lifecycle and what happens at each one
· How a banking customer onboarding process illustrates the full lifecycle
· The shift from ETL to ELT and why it matters for modern data teams
· How regulations like GDPR, SEC Rule 17a-4, and SOX create competing demands on data retention and deletion
· Why the destruction stage is the most neglected and most compliance-critical part of the lifecycle
What Is the Data Lifecycle?
The data lifecycle is the complete sequence of stages that data passes through, from the point it is created or captured to the point it is archived or permanently destroyed. Different frameworks define these stages in slightly different ways: some use five stages, others eight. The core idea is the same.
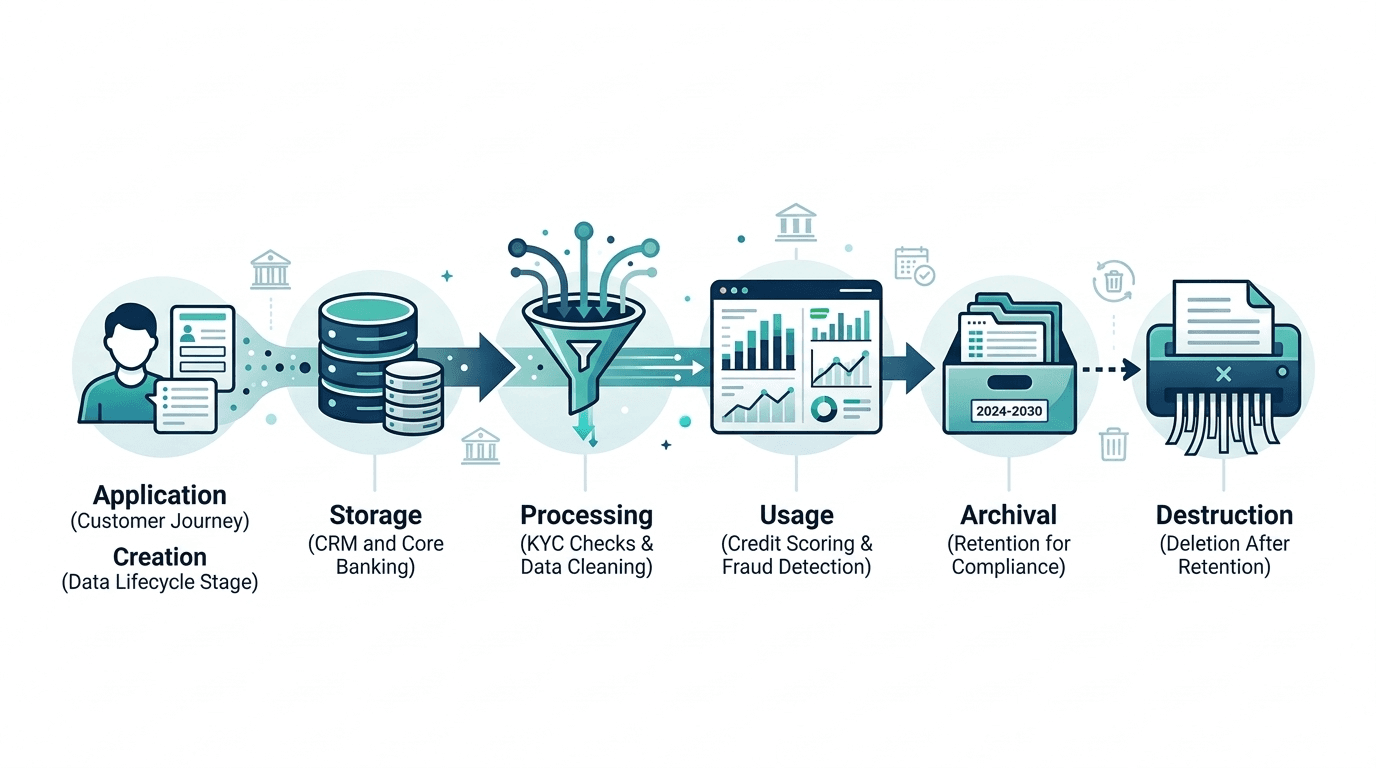
At NeuroNomixer, we use a six-stage framework that balances practical clarity with enough granularity to be useful in regulated environments:
· Creation: data is generated or captured for the first time
· Storage: data is persisted in a system for future use
· Processing: data is cleaned, transformed, and prepared for analysis
· Usage: data is accessed, queried, and applied to decisions
· Archival: data is moved to long-term storage for retention or compliance
· Destruction: data is permanently deleted when it is no longer needed or legally required
These stages are not always linear. Data may cycle between processing and usage multiple times. It may be archived and later retrieved. But the framework provides a mental model for understanding where data is, who is responsible for it, and what governance controls apply at each point. If you are new to thinking about data as a concept, our beginner's guide to what data actually is is a useful starting point.
The Data Lifecycle in Practice: A Banking Example
Abstract stages become meaningful when you see them in context. Let us walk through a real-world scenario: a new customer applying for a bank account.
Stage 1: Creation
The customer fills in an online application form. Their name, address, date of birth, employment details, and identity documents are captured. This is the creation stage: new data enters the organisation for the first time. In financial services, creation also includes data generated by internal systems, such as transaction logs, risk scores, and audit trails.
Stage 2: Storage
The application data is saved to the bank's core systems: a CRM for customer records, a document management system for identity scans, and a relational database for structured application data. Storage is not just about putting data somewhere. It involves choosing the right system for the data type, applying access controls, and ensuring redundancy. Understanding the broader data ecosystem helps clarify where different types of data belong.
Stage 3: Processing
The raw application data is cleaned, validated, and enriched. The bank runs Know Your Customer (KYC) checks against external databases. The data is standardised: addresses are geocoded, names are normalised, income figures are converted to a common format. This stage is where data pipelines do their work, transforming messy inputs into reliable, analytics-ready datasets.
Stage 4: Usage
Now the processed data is put to work. A credit scoring model evaluates the customer's risk profile. A fraud detection system checks for suspicious patterns. A relationship manager reviews the application using a dashboard that aggregates data from multiple sources. This is the stage where data generates value, whether through data-driven decisions, automated workflows, or reporting.
Stage 5: Archival
Once the account is opened and the onboarding process is complete, much of the supporting data moves out of active systems. Identity verification documents are archived to compliant long-term storage. Transaction histories are retained for regulatory purposes. Under SEC Rule 17a-4, certain financial records must be preserved for a minimum of six years. The Sarbanes-Oxley Act requires audit data retention for seven years. Archival is not the end of the lifecycle; it is a holding pattern governed by retention policies.
Stage 6: Destruction
Years later, the customer closes their account. After the legally mandated retention period expires, the bank must destroy the personal data. Under GDPR's Article 17, the Right to Erasure, individuals can also request deletion before the retention period ends, creating a direct tension with financial retention mandates. Destruction must be provable: regulators and auditors need evidence that data was actually deleted, not just that a deletion was scheduled. This is the most neglected stage of the lifecycle, and in many organisations, the most compliance-critical.
How Data Moves: The Shift from ETL to ELT
The processing stage of the lifecycle deserves special attention because it is where the technical architecture of modern data teams lives. For decades, the standard approach was ETL: Extract, Transform, Load. Data was pulled from source systems, transformed in a staging environment, and then loaded into a warehouse. This worked when data volumes were manageable and transformations were relatively simple.
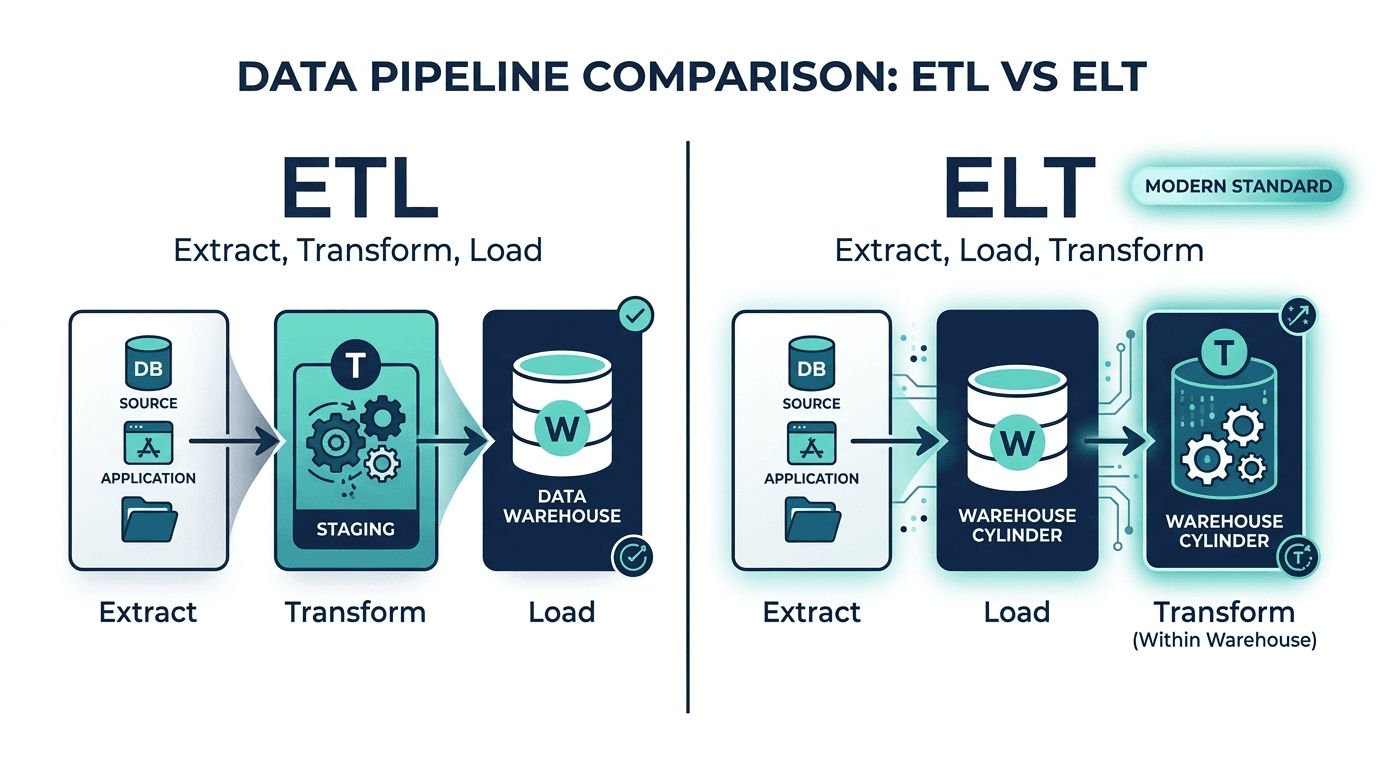
Today, most modern data teams have shifted to ELT: Extract, Load, Transform. Raw data is extracted from sources, loaded directly into a cloud data warehouse (such as Snowflake, BigQuery, or Databricks), and then transformed in place using the warehouse's own computing power. Tools like dbt have become the standard for managing these transformations, bringing software engineering practices (version control, testing, documentation) to data pipelines.
Why does this matter? Because ELT preserves the raw data. When a regulator asks how a credit decision was made, or when a model needs to be retrained on historical data, the original inputs are still available. In financial services, where explainability and auditability are regulatory requirements, this preservation of raw data is not just convenient; it is essential.
Governance Across the Lifecycle
Every stage of the data lifecycle requires governance: the policies, roles, and controls that ensure data is accurate, secure, and compliant. In practice, governance means answering four questions at every stage:
· Who is responsible for this data? Data ownership must be clear. In financial institutions, this often maps to business lines rather than IT departments.
· Who can access it? Access controls should follow the principle of least privilege. Not everyone who needs data in the usage stage should have access during creation or archival.
· How long must it be kept? Retention policies vary by regulation, jurisdiction, and data type. Financial audit data (seven years under SOX), transaction records (six years under SEC 17a-4), and customer PII (five years after account closure under BSA) all have different timelines.
· When and how must it be deleted? Destruction policies must be documented, enforceable, and auditable. GDPR requires that organisations can demonstrate compliance with deletion requests.
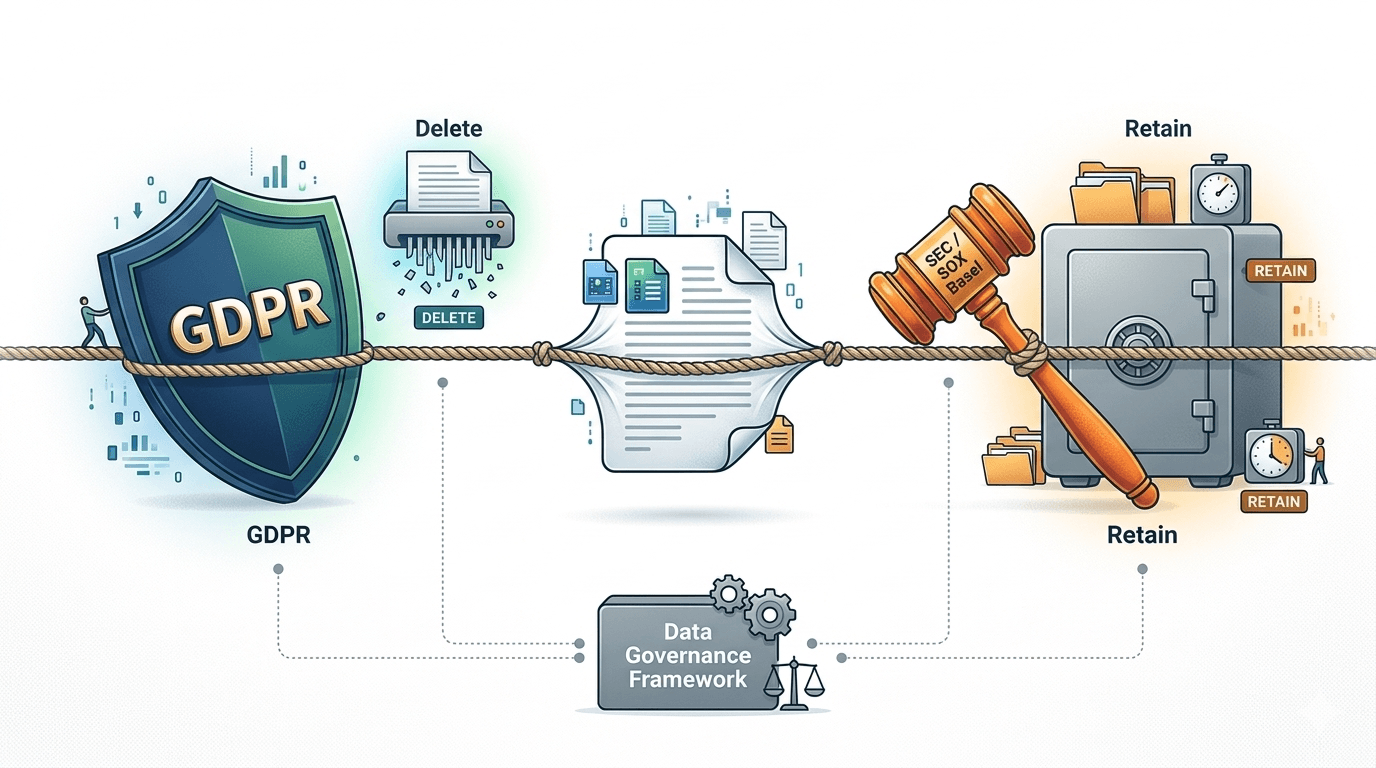
The challenge for financial institutions is that these requirements often conflict. GDPR may require you to delete a customer's personal data upon request, while SEC rules require you to retain transaction records for years. Navigating this tension requires a data governance framework that can handle competing obligations at the field level, not just the dataset level. Understanding how data flows through your organisation's ecosystem is a prerequisite for building that framework.
Data Lineage: Tracking the Journey
As data moves through the lifecycle, knowing where it came from, how it was transformed, and where it ended up becomes increasingly important. This is data lineage: the ability to trace data back to its origin and forward to its consumers.
In regulated industries, lineage is not optional. When a credit scoring model produces a decision, the bank must be able to trace the inputs back through every transformation to the original source data. Standards like OpenLineage are emerging to provide this traceability across modern data platforms. For organisations building AI systems, lineage connects directly to model risk and explainability: you cannot explain a model's output if you cannot verify its inputs.
Data lineage is also how organisations detect and fix data quality issues. If a dashboard shows unexpected results, lineage lets you trace the problem back to its source, whether it is a broken pipeline, a schema change, or a data entry error.
Why the Data Lifecycle Matters Now
Three converging forces make the data lifecycle more important in 2026 than it has ever been.
First, regulatory pressure is intensifying. The EU AI Act requires documented data governance for high-risk AI systems. GDPR enforcement is maturing, with regulators issuing larger fines and scrutinising deletion practices. Data sovereignty requirements are diverging globally, adding complexity for multinational organisations.
Second, AI and machine learning depend on lifecycle discipline. Every ML model is only as good as the data it was trained on. If the creation, processing, and storage stages are poorly governed, the models built on that data inherit every flaw. As we explored in our post on the foundational tools for data careers, understanding how data moves through systems is a core competency for anyone working in analytics or AI.
Third, the cost of data mismanagement is rising. Storage costs, compliance penalties, security breaches, and lost analytical value all compound when organisations do not manage their data lifecycle effectively. The organisations that treat lifecycle management as a strategic capability, rather than an IT concern, will be better positioned to extract value from their data and meet regulatory expectations.
Conclusion: From Sprawl to Strategy
The data lifecycle is not a theoretical framework. It is a practical map for understanding how information enters your organisation, what happens to it, and when it should leave. For financial services, where regulation, risk, and value creation all depend on data quality and governance, getting this right is non-negotiable.
If you are just starting to think about your organisation's data maturity, begin with an inventory. Know what data you have, where it lives, and who is responsible for it. Then map each dataset to the lifecycle stages. You will quickly discover gaps in governance, especially in the archival and destruction stages that most organisations neglect.
In upcoming posts, we will explore how different data roles engage with the lifecycle, and how structured and unstructured data each present unique management challenges. The lifecycle is the foundation; everything else builds on top of it.
Continue Reading
· What Is Data? A Complete Beginner's Guide for the Curious Mind